Suchmaschinen - Search Engines
Inhaltsverzeichnis:
1. Grundlagen
Möglichkeiten,
im Netz Daten zu finden
Problematik
2. Kategorisierung von Suchmaschinen
3. Funktionsweise von Suchmaschinen
Standart
for Robot Exclusion
Politisch
korrekte Bots
4. Agenten
5. Suchalgorithmen
6. Fehlertolerante
Suche von Text
7. Tips / Wissenswertes
8. Glossar
9. Literatur
Bücher
Artikel
Links
10. Prüfungsrelevante Fragen
1. Grundlagen
Möglichkeiten,
im Netz Daten zu finden:
-
Surfen (unsystematisches Verfolgen von Links)
-
Eigene Bookmarks
-
Linksammlungen
-
Kataloge und Register
-
Browsen (systematisches Verfolgen der Links)
-
Gateways
-
Gezielte Suche durch Abfrage von Suchmaschinen
-
Agenten
Problematik
Probleme:
-
Indizierung von bestimmten Daten nicht immer möglich
-
Videos
-
Bilder und Grafiken
-
Töne
-
Zu viele Treffer bei der Suche
-
Ungeeignete Suchergebnisse
-
Fehlende Aktualität der Suchergebnisse
-
Suche nach Worten deren Schreibweise unbekannt ist. -> phonetische Suche
-
synonyme, Thesaurus, Unterbegriffe, Oberbegriffe, Gegenteile werden nicht
gefunden.
-
Was Suchmaschinen nicht finden
-
Geschützte Dokumente (Paßwort, Firewalls, nicht öffentlich)
-
Dynamische Dokumente / Datenbankgateways (Dokumente die erst erstellt werden)
-
Robots können Qualität der Seiten nicht bewerten
-
Hohe Netzlast durch Bots.
Suchmaschinen sind die richtige Wahl wenn es darum geht:
-
schnell herauszufinden, ob überhaupt etwas zu einem bestimmten Thema
zu finden ist
-
konkrete Informationen, Produkte oder Personen zu lokalisieren
-
Dinge zu finden, von denen man weiß daß sie irgendwo im Internet
zu finden sind
Thematische Verzeichnisse dagegen sind eher geeignet, wenn man:
-
sich ganz generell einen Überblick über die vielfältigen
Angebote machen will
-
sich eine Überblick darüber verschaffen will, was zu einem bestimmten
Thema zu finden ist
Informationen in einem größeren Zusammenhang sucht
2. Kategorisierung von Suchmaschinen
Art der Ergebnisdarstellung (Welche Treffer werden als erstes aufgelistet)
-
Viele Anfragen während der letzten Zeit
-
Hohe Anzahl der Übereinstimmungen
Art der Indizierung
-
Volltext (Die ganze Seite wird indiziert)
-
Header (Nur der Header der Seite wird indiziert
Art des Datenerwerbs
-
Bots
-
Menschliche Recherche
-
Überwachung von Surfgewohnheiten der User
Kataloge und Register
Kataloge und Register werden in der Regel von Menschen generiert, dadurch
sind sie nicht so umfassend wie computergenerierte Indexe. Man kann aber
von einer höheren Qualität des Index ausgehen, da der Ersteller
des Index die Qualität der Seite bewerten kann und dementsprechend
nur hochwertige und passende Seiten in den Katalog integrieren wird.
Meta-Suchsysteme
Meta-Sucher bieten einen Weg aus diesem Dilemma. Sie benutzen mehrere Recherchedienste
gleichzeitig, integrieren die Ergebnisse und geben sie gesammelt wieder
aus.
Harvest-Systeme
Harvest-Systeme arbeiten mit Bots. Diese laufen aber im Gegensatz zu normalen
Suchmaschinen lokal auf dem zu indizierenden Server. Sie schicken dann
nur den generierten Index zum Suchdienst-Server, anstatt die komplette
Seite anzufordern. Dadurch wird die Netzlast reduziert und keine Bandbreite
verschwendet.
3. Funktionsweise von Suchmaschinen
Eine Suchmaschine unterteilt sich in zwei große Komponenten, die
Wissenserwerbskomponente und die Wissensbasis. In der Wissensbasis befindet
sich auf dem Server des Betreibers. In ihr ist ein Index der Internetseiten
gespeichert. Die Wissenserwerbskomponente dient dazu, den Index auf dem
neuensten Stand zu halten. Der Index ist meistens in einer Datenbank gespeichert.
Da niemand in der Lage ist, die Datenbank auf einem aktuellen Stand zu
halten, setzt man dazu Programme, sogenannte Robots ein.
Robots auch Bots genannt durchsuchen das Internet, indem sie sich durch
die Links der HTML-Seiten hangeln. Die gelesenen Seiten werden dabei indiziert.
Bots werden z.B. in Perl erstellt. Der Index wird ständig aktualisiert.
Tote Links werden entfernt und neue Seiten hinzugefügt. Bei einem
Vollindex von mehren Millionen Seiten treten sogenannte Totzeiten auf,
da es eine Zeit dauert bis eine bereits indexierte Seite aktualisiert wird.
So kann der Index einer Seite teilweise mehrere Wochen alt sein. Seiten
mit hohen Zugriffszahlen werden aus diesem Grund von den Bots öfter
gescannt, um eine hohe Aktualität zu gewährleisten.
Stellt nun ein Benutzer eine Abfrage an die Suchmaschine, so wird diese
auf der lokalen Datenbank ausgeführt. Die Ergebnisse werden dann als
Links auf die entsprechenden Seiten zurückgeliefert.
Standart for Robot Exclusion
Der Standard for Robot Exclusion dient zur Einschränkung der Zugriffsrechte
von Bots auf Server. Es handelt sich dabei wohlgemerkt um einen freiwilligen
Standart. Niemand der Bots programmiert ist verplichtet, den Standart einzuhalten,
und es gibt auch kein Gremium, daß Verstöße aufspürt.
Dennoch hat er sich dieser Standart etabliert. Dazu wird einfach im Rootverzeichnis
des Servers eine Datei namens robots.txt erzeugt. In ihr befinden sich
unter anderem folgende Zeilen:
# go away
User agent: *
Disallow: /
Über die Felder User agent lassen sich bestimmte Agenten aussperren.
Mit Disallow lassen sich einzelne Verzeichnisse dicht machen.
Hat man kein Zugriffsrecht auf das Rootverzeichnis des Servers, so
kann man sich beim Schreiben von HTML-Dokumenten auch mit einem geeigneten
Header behelfen. Auch hierfür existieren Standards, um den Zugriff
auf Seiten einzuschränken. Mit sog. Meta-Tags läßt sich
die Indizierung der Texte steuern.
Politisch korrekte Bots
Es gilt weiterhin folgende Richtlinien beim Schreiben von Bots zu beachten.
HTTP unterstützt ein Feld "User-agent" mit dem sich ein Browser identifizieren
kann. Robots sollten sich damit ausweisen. Eine ähnliche Funktion
hat das "From" Feld. In ihm sollte die Emailadresse des Bot-Betreibers
eingetragen werden. Macht ein Bot Probleme, so kann der Verursacher darüber
informiert werden.
4. Agenten
Charakteristische Merkmale von Agenten:
Ein Agent handeln autonom, er kennt seine Fähigkeiten,
hat Kontrolle über seine Handlungen, und kann daher ohne direkten
Eingriff des Benutzers tätig werden.
Agenten müssen in der Lage sein, mit Artgenossen zu kommunizieren.
Stoßen sie an die Grenzen ihrer Leistungsfähigkeit, nehmen sie
Kontakt mit anderen Agenten auf und suchen nach Helfern.
Für das Überleben in dynamischen Umgebungen muß die
Software in der Lage sein, unvorhergesehen Ereignisse beim weiteren
Vorgehen zu berücksichtigen. (Reaktivität)
Agenten müssen Eigeninitiative zeigen. Sie sollen nicht
nur reagieren, sondern haben übergeordnete Ziele, die sie selbständig
verfolgen.
5. Suchalgorithmen
Der Einsatz von geeigneten Suchalgorithmen beschleunigt die Volltextsuche
teilweise bis zum Faktor 6. Diese Algorithmen machen sich dabei aus vorhergehenden
Abfragen gewonnene Information zunutze, um das Suchmuster mit jedem Schritt
möglichst weit vorwärts zu schieben.
Beachte:
Die String-Vergleiche werden bei T-search und T++-search
von rechts nach links durchgeführt!
Der zu suchende String wird ans Ende des Textes
kopiert, dadurch wird eine performancefressende EOF-Abfrage umgangen.
Brute Force:
|
Position
|
1 |
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
| Text |
a
|
b
|
c
|
a
|
a
|
c
|
b
|
c
|
a
|
d
|
a
|
b
|
a
|
c
|
|
Muster
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
|
|
| |
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
|
| |
|
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
Standardmäßiges Vorgehen mit Brute Force.
Quicksearch:
|
Position
|
1 |
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
| Text |
a
|
b
|
c
|
a
|
a
|
c
|
b
|
c
|
a
|
d
|
a
|
b
|
a
|
c
|
|
Muster
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
a
|
b
|
a
|
c
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
a
|
b
|
a
|
c
|
Quicksearch ermittelt anhand des Zeichens hinter dem Text, wie weit
es weiter schieben darf.
T-search:
|
Position
|
1 |
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
| Text |
a
|
b
|
c
|
a
|
a
|
c
|
b
|
c
|
a
|
d
|
a
|
b
|
a
|
c
|
|
Muster
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
a
|
b
|
a
|
c
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
a
|
b
|
a
|
c
|
a
|
b
|
a
|
c
|
T-search nutzt Informationen aus erfolgreichen Vergleichen aus, um noch
größere Sprünge zu machen.
T++-search:
|
Position
|
1 |
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15 |
16 |
|
Text
|
a
|
b
|
c
|
a
|
a
|
c
|
t
|
e
|
D
|
i
|
s
|
k
|
e
|
t
|
t
|
e
|
|
Muster
|
D
|
i
|
s
|
k
|
e
|
t
|
t
|
e
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D
|
i
|
s
|
k
|
e
|
t
|
t
|
e
|
T++-search berücksichtigt, weiterhin, daß ein Shift um drei
Zeichen nicht in Frage kommt, da "ke" dann auf "te" liegen würde.
6. Fehlertolerante Suche von
Text
Eine leicht zu verstehende und implementierende Art der Textindizierung
ist die durch Trigramme. Das Suchwort wird in dreier-Buchstabengruppen
zerlegt.
Bsp.: "Reisebus" in RE, REI, EIS, ISE, SEB, EBU, BUS, US.
Es werden in einem Index über alle Trigramme diejenigen Texte
herausgesucht, in denen alle/viele Trigramme vorkommen.
Optimierung des Verfahrens:
-
Index nur für seltene Trigramme z.B. < 10%
-
Häufig auftretende Trigramme zu längeren n-Grammen zusammenfassen,
solange bis n-Gramme selten auftreten.
-
Verwendung von mehreren n-Grammen gleichzeitig. z.B. Länge 3 und 5
7. Tips / Wissenswertes
-
Altavista sucht streng nach Wörtern, Lycos bezieht aus dem englischen
abgeleitete Wörter in die Suche mit ein.
-
Altavista: LiveTopics analysiert den gefundenen Datenbestand und stellt
das Ergebnis grafisch in Gestalt eines semantischen Wortfeldes dar.
-
Altavista: 30 Millionen Seiten Vollindex Alphaserver 840 zehn Prozessoren,
6GByte Hauptspeicher 210GByte Festplatte ( August 1996).
-
Excite (rund 50 Mio. indizierte Seiten) (Stand 10/97)
-
Bedienungsanleitung der Suchmaschinen lesen.
-
Wenn möglich Beschränkung auf Suchmaschinen die nur bestimmte
Bereiche indizieren, da schnellere Abfragen und größerer Index
in Teilbereich.
-
Ein effizienter Index ist häufig der Schlüssel zur Leistungsfähigkeit
der entsprechenden Recherchemaschine. Der Aufbau dieser Datenstruktur legt
zum einen die möglichen Anfragen fest, zum anderen beeinflußt
der Index auch die Antwortgeschwindigkeit auf eine Anfrage. Wie die Suchmaschinen
der einzelnen Hersteller ihre Indexe im Detail aufbauen ist daher ein gut
gehütetes Firmengeheimnis.
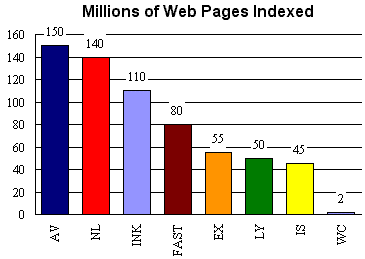
Stand 01.05.99
KEY: AV=AltaVista, NL=Northern Light, INK=Inktomi, FAST=FAST
EX=Excite, LY=Lycos,
IS=Infoseek, WC=WebCrawler
Anmerkung: Geschätzte Seitenzahl 01.05.99 ca. 550 Mio.
Weitere Infos
/ Diagramme
8. Glossar
| Robot |
Programm, das Internetseiten indiziert |
| URL |
Uniform Ressource Locator |
| Smart browsing |
Verweis auf themenbezogene Seiten durch Auswertung von Benutzerverhalten |
| Meta-Suchdienste |
Suchdienste, die Abfragen an mehrere andere Suchdienste stellen und
die Ergebnisse dann auswerten und aufbereiten |
| Spider, Worm |
siehe Robot |
| Agenten |
Programme die selbständig Aufgaben des Anwenders übernehmen
und ihn bei der Arbeit unterstützen. |
9. Literatur:
Bücher
Effektive Suche im Internet; Ulrich Babiak; Köln 1997; O´Reilly-Verlag;
185 Seiten; 29 DM; ISBN 3-930673-68-1
Artikel
Wortschätze heben, Volltext-Retrievalsysteme; c't August 96
S.160
Software mit Managerqualitäten, Agenten-Programme mit Überzeugungen
und Absichten; c't 15/97 S.234
Roboter-Baukasten, WWW-Automaten in Perl selbst programmieren; c't
März 96 S.164
Autopiloten fürs Netz, Intelligente Agenten - Rettung aus der
Datenflut; c't März 96 S.156
Blitzfindig, Texte durchsuchen mit T-Search; c't August 97 S.292
Text-Detektor, Fehlertolerantes Retrieval ganz einfach; c't April 97
S.386
Links
Searchengines:
http://www.1079.com/book/3search.htm
http://www.fh-duesseldorf.de/WWW/DOCS/FB/ETECH/DOCS/itk/Suchmasch_Vortrag.html
http://searchenginewatch.com/
http://o2f.fh-potsdam.de/jan/searchengines/index.html
http://www.ub2.lu.se/tk/demos/DO9603-meng.html
http://www.ub.uni-bielefeld.de/biblio/search/smkurs.htm
http://trumpf-3.rz.uni-mannheim.de/www/sem96w/bb/SuchenFinden.html
http://www.suchfibel.de/5technik/5frame2.htm
Robots:
http://www.bn-nd-sob.baynet.de/pub/Doku/robotfaq.htm
http://info.webcrawler.com/mak/projects/robots/articles.html
http://bots.internet.com/faqs/
http://www.botspot.com
Internet Dictionary:
http://www.msg.net/kadow/answers/answers.html
10. Prüfungsrelevante Fragen
1. Was versteht man unter einem Meta-Suchdienst
Ein Meta-Suchdienst, stellt Abfragen an mehrere
andere Suchdienste.
Er wertet die Ergebnisse der anderen Suchdienste
aus und bereitet sie auf.
2. Was ist ein "Bot"
Ein Bot ist ein Programm zur Indizierung von
Internetseiten.
3. Nennen Sie vier Probleme, die sich beim Einsatz von Suchmaschinen
ergeben.
-
Indizierung von bestimmten Daten nicht immer möglich (Videos, Bilder
und Grafiken, Töne)
-
Zu viele Treffer bei der Suche
-
Ungeeignete Suchergebnisse
-
Fehlende Aktualität der Suchergebnisse
-
Robots können Qualität der Seiten nicht bewerten
-
keine phonetische Suche
-
synonyme, Thesaurus, Unterbegriffe, Oberbegriffe, Gegenteile werden
i.d.R. nicht gefunden.
-
Hohe Netzlast durch Bots
-
Was Suchmaschinen nicht finden
Geschützte Dokumente (Paßwort, Firewalls, nicht öffentlich)
Dynamische Dokumente / Datenbankgateways (Dokumente die erst erstellt
werden)